How far can we go with ImageNet for Text-to-Image generation?
Training high-quality text-to-image generation models with 1/10th the parameters, 1/1000th the training images, in about 500 H100 hours

Overview
The common belief in text-to-image (T2I) generation is that larger training datasets lead to better performance, pushing the field towards billion-scale datasets. However, this “bigger is better” approach often overlooks data efficiency, reproducibility, and accessibility, as many large datasets are closed-source or decay over time.
Our work challenges this paradigm. We demonstrate that it’s possible to match or even outperform models trained on massive web-scraped collections by using only ImageNet, a widely available and standardized dataset. By enhancing ImageNet with carefully designed text and image augmentations, our approach achieves:
- A +6% overall score over SD-XL on GenEval and +5% on DPGBench, using models with just 1/10th the parameters and trained on 1/1000th the number of images.
- Our models (300M-400M parameters) can be trained with a significantly reduced compute budget (around 500 H100 hours).
- We also show successful scaling to higher resolution (512x512 and 1024x1024) generation under these constraints.
This research opens avenues for more reproducible and accessible T2I research, enabling more teams to contribute to the field without requiring massive compute resources or proprietary datasets. All our training data, code, and models are openly available.
Adopting ImageNet for Text-to-Image Generation
1. Long Informative Captions
ImageNet’s original labels are simple class names, but the images contain rich visual information. We generate highly detailed captions that describe those images.
2. Image Augmentations to Reduce Overfitting and Increase Compositionality
Models trained on ImageNet (even with text augmentation) can suffer from early overfitting due to its relatively small scale (1.2M images) and struggle with complex compositions due to its object-centric nature. We implement two Image Augmentation (IA) methods (CutMix and Crop) to mitigate those issues.
These IA strategies, when combined with text augmentation (TA+IA), demonstrably reduce overfitting and significantly improve compositional reasoning (+7 points on GenEval’s “Two Objects” sub-task).

Qualitative comparison: Text-Augmentation (TA, first, third columns) vs Text+Image Augmentation (TA+IA second, last columns) for four prompts.
Comparison with State-of-the-Art
We compare our $512^2$ resolution model against the state-of-the-art. Despite using significantly fewer resources (parameters and training data), its demonstrates strong performance compared to established large-scale models.
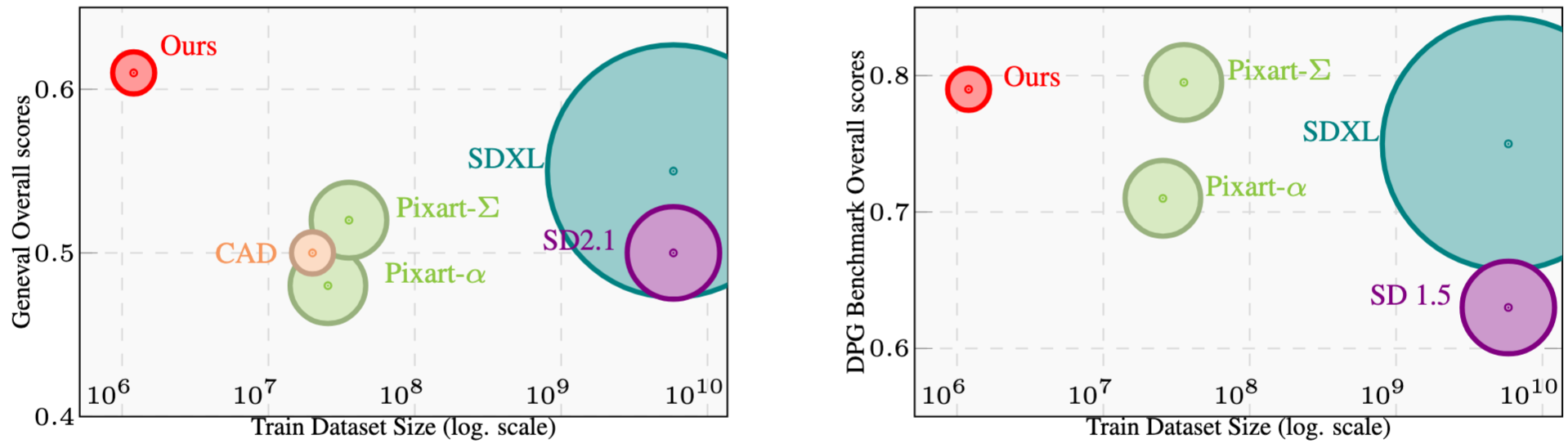
Quantitative results on GenEval (left) and DPGBench (right). The size of the bubble represents the number of parameters. Our models (labeled "Ours") achieve superior or comparable performance to much larger models trained on vastly more data.
Gallery




















Example generations from our models following various text prompts. Use arrow buttons or swipe to navigate through the gallery.
Task Specific Finetuning: Aesthetic Quality
We demonstrate that our models can be effectively finetuned for specific tasks. Below, we compare our aesthetically-finetuned model against state-of-the-art models (SD-XL, PixArt, SD3-Medium) on the same prompts.








































Side-by-side comparison of our aesthetically-finetuned model against state-of-the-art T2I models. Our model (highlighted) shows competitive or superior visual quality despite being trained on significantly less data. Use arrow buttons to navigate through different prompts.
BibTeX
@article{degeorge2025farimagenettexttoimagegeneration,
title ={How far can we go with ImageNet for Text-to-Image generation?},
author ={Lucas Degeorge and Arijit Ghosh and Nicolas Dufour and David Picard and Vicky Kalogeiton},
year ={2025},
journal ={arXiv},
}
Acknowledgments
This work was granted access to the HPC resources of IDRIS under the allocation 2025-AD011015436 and 2025-AD011015594 made by GENCI, and by the SHARP ANR project ANR-23-PEIA-0008 funded in the context of the France 2030 program. The authors would like to thank Alexei A. Efros, Thibaut Loiseau, Yannis Siglidis, Yohann Perron, Louis Geist, Robin Courant and Sinisa Stekovic for their insightful comments, suggestions, and discussions.
Published: February 2025